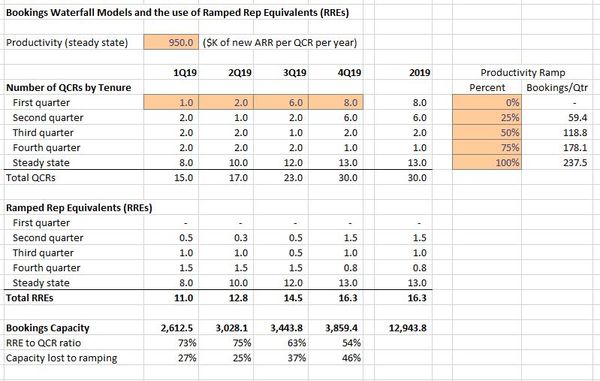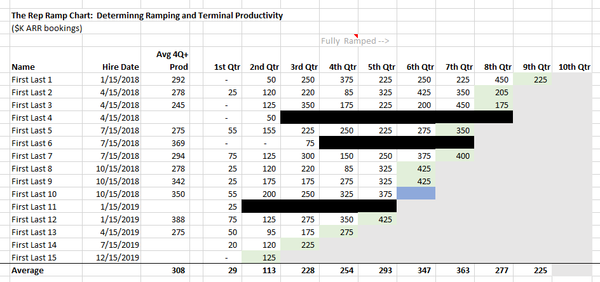
SaaS
Measuring Ramped and Steady-State Sales Productivity: The Rep Ramp Chart
You start by listing every rep your company has ever hired in order by hire date. You then record their sales productivity (typically measured in new ARR bookings) for their series of quarters with the company, up to and including their current-quarter forecast (which you shade in green).